tl;dr A closed-form formula is a means of expressing a variable in terms of functions that we have got names for. The set of functions that we have got names for is a pure accident of human history. Thus having a closed-form formula for an object of study is also merely an accident of human history and doesn’t say anything fundamental about the object.
The essence of scientific investigation
Scientists like understanding things. A good test of understanding is the ability to predict. For example, we can claim that we have understood gravity because we can predict with amazing accuracy where the moon, for example, is going to be at any given time in the future.
In the next few paragraphs, I am going to want to make extremely general claims and that will require me to talk about some very abstract concepts. So let me talk about those abstract concepts first.
Most of the things that we have tried to understand in the history of scientific investigation can be thought of as an abstract number crunching device. The moon, for example, is something that we see in the sky at a particular angle at a given time. So we can think of the moon as a device that takes time as input and turns it into a particular position in the sky. We can denote time by a number t and the position by two numbers x and y. Thus moon converts t into x and y.
The number crunching that the moon does is not arbitrary. If one observes the moon for a while, it is easy to start seeing some patterns. Some obvious patterns are immediately visible. For example, there is a certain continuity in the way it moves, i.e., its position in the sky does not change too much in a short period of time. There are other very non-obvious patterns too. These patterns, in fact, required centuries of scientific investigation to uncover.
When we are trying to understand the moon, we are trying to understand this pattern. More precisely, we want to write down a set of rules that perform the same number crunching as the moon does, i.e., if we start with a t and apply those rules on t one by one, we get an x and a y whose values match exactly with the values that the moon’s number crunching would have given us. Now, I am not claiming that understanding the relationship between x, y and t tells us everything about the moon. Of course, it doesn’t say anything about whether there is oil on the moon’s surface. But let me just use “understanding the moon” as a metaphor in the rest of the article for understanding this specific aspect of the moon’s motion.
This is not specific to the moon, by the way. Consider some other subject of investigation. For example, the flu virus. One crude way of modelling the flu virus as a number crunching device is to say that it converts time into the expected number of people infected. That’s a very high level picture and we can make the model more informative by adding some more parameters to the input. For example, say, the average temperature that year, the humidity etc. The output can also be modified. We can, for example, make the output a vector of probabilities, where probability number i tells us how likely is it that person number i will get infected by the flu virus. There could be many ways of understanding the flu virus, but once we have asked one specific question about it, we have essentially modelled it as a number crunching device that converts some set of numbers into another set of numbers.
The main challenge of scientific investigation is that we do not usually have access to the inner workings of the number crunching device under investigation. In this sense, it is a black box. We only get to see the numbers that go in and the numbers that come out. Just by observing a large number of these input-output pairs, we take up the task of figuring out what’s going on inside the black box. We know that we have figured it out if we can replicate it, i.e., once we have constructed a set of our own rules that have the same behavior as the black box.
Things get interesting once we try to understand what kinds of rules we are allowed to write. For example, do we really have to write those rules? Is it fine if I hire a person who knows the rules and when given a time t, always outputs the correct x and y, the x and y that the moon itself would have churned out? Is it still fine if the person I have hired only understands the rules and can replicate the correct input-output behavior but can not explain the rules to me? If that is fine, then how about creating a machine, instead of hiring a person, that manifests the same input-output behavior in some way? For example, may be, the machine is simply a screen with a pointer and a dial so that when you set a specific t on the dial, the pointer moves to the correct x and y coordinates on the screen? Is that fine? Or may be, the machine is just a giant rock revolving around a bigger rock so that when a person standing on the bigger rock looks up at time t, he can see the smaller rock exactly at coordinates described by the corresponding numbers x and y?
I don’t know which of the scenarios above should be considered a “valid” understanding of the moon and which ones should not. But it seems clear that there can be several different ways of “writing” the set of rules. The primitive way of doing this was to write the set of rules as a closed-form formula.
What is a closed-form formula?
x = 2t + 1 is a closed-form formula. So is x = sin(t) + cos(t).
Until high school, I was under the impression that in order to understand the moon, one was required to present some such closed-form formula, i.e., express both x and y as functions of t. But that’s an unnatural constraint.
For example, what if x was a slightly weirder function? Say, x was 2t+1 for t < 1000 and sin(t) + cos(t) for t > 1000? May be we would still accept that, mainly because there exists a conventional way of writing such piecewise functions in math. But what if x was something even more weird? For example, say x was equal to the smallest prime factor of t? Or may be x was something that just cannot be written in one sentence? May be x was just given by a sequence of instructions based on the value of t, so that if you started with a value of t and followed those instructions one by one, you would end up with the value of x?
The punchline of this argument is that sin(t) (or even 2t+1, for that matter) is already such a set of instructions. Just because human beings, at some point, decided to give it a name doesn’t mean it is more fundamental than any other set of instructions for converting t into x. Thus in the process of understanding the moon, one should not worry about coming up with a closed-form formula.
At the same time, it is clear that some ways of writing the rules are better than others. For example, having a moon’s life-size replica revolve around the earth’s life-size replica as your set of rules is a bit inconvenient from the point of view of making predictions.
What, then, is the “correct” way of writing the rules? I want to claim that the answer to this question can be found by understanding computation and, specifically, the area of computational complexity. But I will not make this article any longer.
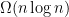 time) and the travelling salesman problem (the general version is hard to approximate, but the Euclidean case has a PTAS).
time) and the travelling salesman problem (the general version is hard to approximate, but the Euclidean case has a PTAS). and
and  of
of  points each in the two dimensional plane. This defines a complete weighted bipartite graph where we create a node for each point in
points each in the two dimensional plane. This defines a complete weighted bipartite graph where we create a node for each point in 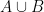 and an edge
and an edge 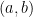 for all
for all 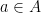 and
and  . To each edge
. To each edge  and
and  . The question, then, is to compute the minimum weight perfect matching in this graph in
. The question, then, is to compute the minimum weight perfect matching in this graph in 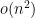 time. Currently, the best known algorithm takes
time. Currently, the best known algorithm takes 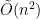 time where
time where  hides logarithmic factors. If we don’t care about the accuracy, it is possible to reach almost linear time, that is, there exists a near linear time algorithm that finds a
hides logarithmic factors. If we don’t care about the accuracy, it is possible to reach almost linear time, that is, there exists a near linear time algorithm that finds a 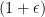 -factor approximation for any
-factor approximation for any  . Getting a subquadratic approximation algorithm is a good sign because often approximation algorithms can be made exact by setting the
. Getting a subquadratic approximation algorithm is a good sign because often approximation algorithms can be made exact by setting the  appropriately, if we know something about the solution space. For example, if we know that the set of all possible weights achievable by a perfect matching is an integer in the range
appropriately, if we know something about the solution space. For example, if we know that the set of all possible weights achievable by a perfect matching is an integer in the range ![{[1..n^2]}](https://s0.wp.com/latex.php?latex=%7B%5B1..n%5E2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we can get an exact solution by setting
, we can get an exact solution by setting 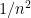 . Of course, this approach has obvious caveats, including a) that we do not know anything about the set of possible weights achievable by the perfect matchings and b) that setting
. Of course, this approach has obvious caveats, including a) that we do not know anything about the set of possible weights achievable by the perfect matchings and b) that setting 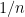 will blow up the running time.
will blow up the running time. integer grid. In this case an *additive* approximation algorithm is known that runs in
integer grid. In this case an *additive* approximation algorithm is known that runs in 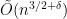 time,
time,  being a small positive constant. Here the
being a small positive constant. Here the  and polynomial factors in
and polynomial factors in 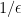 . From now on, we will also hide the
. From now on, we will also hide the 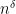 in the
in the  integers, each in the range
integers, each in the range ![{[0..\Delta]}](https://s0.wp.com/latex.php?latex=%7B%5B0..%5CDelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Sums of square roots of integers are, for many reasons, very interesting for the algorithms community and thus have been studied extensively. It is known, for example, that for any two sets of
. Sums of square roots of integers are, for many reasons, very interesting for the algorithms community and thus have been studied extensively. It is known, for example, that for any two sets of 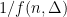 where
where  is polynomial in
is polynomial in 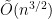 time exact algorithm was shown for the case when points lie on a
time exact algorithm was shown for the case when points lie on a  of those shapes. For example, for the case of halfplanes (i.e., a line and one of its sides), one can easily show using induction on the number of lines that the dual shatter function is polynomial. Notice that when incrementally adding a halfplane to a partially built Venn diagram of halfplanes, the number of new cells created is equal to the number of cells this new halfplane’s boundary intersects. Since a new line can intersect an old line at most once, the number of cells it intersects is at most the number of lines already present. Thus the dual shatter function is
of those shapes. For example, for the case of halfplanes (i.e., a line and one of its sides), one can easily show using induction on the number of lines that the dual shatter function is polynomial. Notice that when incrementally adding a halfplane to a partially built Venn diagram of halfplanes, the number of new cells created is equal to the number of cells this new halfplane’s boundary intersects. Since a new line can intersect an old line at most once, the number of cells it intersects is at most the number of lines already present. Thus the dual shatter function is 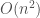 . Simiarly, for any shape that satisfies the property that boundaries of two instances of the shape always intersect in a constant number of places, the dual shatter function is bounded from above by a polynomial.
. Simiarly, for any shape that satisfies the property that boundaries of two instances of the shape always intersect in a constant number of places, the dual shatter function is bounded from above by a polynomial. edges has a maximum independent set of size at least
edges has a maximum independent set of size at least  .
.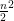 edges and an independent set of size
edges and an independent set of size  .
.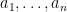 , the mean is the number that minimizes the function
, the mean is the number that minimizes the function  . Thus the averaging step above can be seen as a step where a person is trying to minimize the cost incurred with respect to the cost function
. Thus the averaging step above can be seen as a step where a person is trying to minimize the cost incurred with respect to the cost function 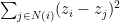 . Here
. Here  represents the neighborhood of
represents the neighborhood of  , i.e., the set of friends of
, i.e., the set of friends of  different bins?
different bins? .
. .
. NP, an NP-hard problem cannot be solved in polynomial time. This means that there cannot exist an algorithm that, for all possible inputs, computes the corresponding output in polynomial time. However, NP-harndess doesn’t prohibit the existence of an efficient algorithm for only a subset of the possible inputs. For example, there is a constant time algorithm for any problem that solves it for a constant number of instances. The algorithm just has a lookup table where the outputs of all the constant number of inputs are stored.
NP, an NP-hard problem cannot be solved in polynomial time. This means that there cannot exist an algorithm that, for all possible inputs, computes the corresponding output in polynomial time. However, NP-harndess doesn’t prohibit the existence of an efficient algorithm for only a subset of the possible inputs. For example, there is a constant time algorithm for any problem that solves it for a constant number of instances. The algorithm just has a lookup table where the outputs of all the constant number of inputs are stored. inputs of size
inputs of size  with a separating triangle
with a separating triangle  .
. 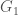 and
and 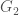 such that
such that  and
and  . If
. If  of maximal planar graphs without any separating triangles. Now, consider a graph whose nodes represent elements of the set
of maximal planar graphs without any separating triangles. Now, consider a graph whose nodes represent elements of the set  . The theorem by Jackson and Yu states that if
. The theorem by Jackson and Yu states that if 