I have been blogging at GoodBlogs. It’s a nice new website that gives you money if your blogs get upvoted to the main page. Here’s my most recent blogpost – http://www.goodblogs.com/view-post/Texbook-that-teaches-how-to-swim .
And here’s the text pasted from the original post –
Learning American history is different from learning how to swim. You can learn American history by reading a textbook about it, but I don’t think there exists someone who read a textbook on swimming, jumped into water and started to swim. Why are some skills so different from others in this respect? Wouldn’t it be awesome if all skills in the world could be learned just by reading a textbook? Can anything be done so that this does happen?
American history can be learned by reading a book because it mostly consists of facts and they can be easily described in a book. So any skill that consists of a collection of information can be transfered by encoding the information in some form (in this case, a book) and passing it on. Is swimming a collection of information too? If you think about it, it actually is. If you study in detail exactly what a swimmer does and exactly why he is able to swim, you will realize that his body is following certain rules. For example, if you feel some flow of water in this direction, then push water away in this direction, or, fold your legs a bit at the knees, then apply some force with the muscles in your thighs etc. Indeed, the brain is finally an information processing device. All it does is that it gets information from different sensory organs, uses it to decide upon an action and sends instructions to different parts of the body so that the action is executed. Whatever information processing the brain does while swimming is also just a piece of information, and, in principle, can be written down in the form of a book and transfered to others. But people learned swimming way before they understood the exact mechanism with which we swim. If you talk to an expert swimmer, he will most probably not know the exact mechanism either. He just somehow gets it. For him, the rules are all of the form, “when you feel this way, you should move these muscles this way,” where the ‘this’ are vaguely defined somewhere deep inside his brain.
So can a texbook for swimming be written? In principle, yes. You just describe the precise set of rules that your brain follows in excruciating details including the exact muscles it moves by exactly what amount when exactly what happens to the water around you. But this textbook will hardly be useful. If you read this textbook and memorize all the rules and jump into water, by the time you understand the force of the water stream and try to decide which muscles you are going to move, you will already be twenty meters deep into the water surprised about the fact that you haven’t had any oxygen in a long while now.
There are other skills that are similar to swimming in this sense. For example, consider learning to play the piano. Even Bach’s Toccata and Fugue in D minor can be written down on a piece of paper using weird symbols that encode the sequence in which you have to press the keys and for how long and how hard and so on. In principle, you could just pick up the staff notation and go through it and you would know exactly how to play the song. But once again, once you begin to understand what’s the next key to press, the audience will probably already lose track of which song you are playing and will start leaving for home.
The thing that’s common with these kinds of skills is that even though writing a textbook about them is useless, if you are allowed to slow time down, it might still be possible to learn the skill just by reading the textbook. For example, in the case of swimming, if somehow the laws of physics slowed down and let you think and calculate your next moves before applying gravity on you, you would be able to swim just by reading the textbook. Also, if the audience were a bit patient and did not lose track of the song so easily, it would be possible for you to just read the staff notation and play the song without any practice.
But now consider cooking. Suppose you want to learn enough cooking so that you can design recipes that you like. Can a textbook be written that gives you exactly this skill? The textbook will once again need to specify some rules in detail. For example, what exactly happens when you add ginger to a recipe? How exactly does it change the taste? Or what happens when you bake something in the oven instead of deep frying? The problem with these questions is that the answer just cannot be specified in a precise way. For example, what exactly is the difference between deep frying and baking? How do you explain this to someone who has never tasted food that’s deep fried or baked? How do you explain to someone the taste of anything if that person has not had that thing (or something similar) before? You can’t. You have to tell him that here, this is baked and this one is deep fried; taste and find out the difference. All other methods are just vague and not sufficient to teach cooking to someone. So in this sense cooking is different from both learning American history and learning how to swim.
So this seems to define three different categories of learnable skills – 1. those that can be taught through textbooks (eg., American history), 2. those that can be taught through textbooks only if one is allowed to slow down time (eg., swimming) and 3. those that just cannot be taught through textbooks (cooking).
Reducing the category number of a skill will be a good progress for science. For example, bringing some skill from category 3 to category 2 will be quite cool. How would one do that with, say, cooking? Well, we will need to make things precise. We will somehow need to quantify the different tastes and figure out exactly how much of which taste is contained in what ingredient. Then, a typical textbook on cooking will say things like, “one cubic centimeter of turmeric contains 3 units of spiciness, 4 units of something and 2 units of something else.” There will be tests for understanding what kinds of tastes you like. Then, whenever you want to cook something delicious, you will have to look at the book for measurements and pick something that brings the taste into the range that you like.
Bringing a skill from category 2 down to category 1 will be quite different. Well, if we are allowed to cheat by using machines, then we are already doing that. We have machines that can swim. We have submarines that can take us inside water and follow our instructions about where we want to go. And to teach these machines, one only needs to give them some information in the form of computer programs. If we are not allowed to cheat, then one will have to figure out some way so that our brains are able to do all the calculations really fast, so that we can decide which muscles to move in real time. We will somehow need to augment our brains, perhaps by building machines inside it, if not outside.
 from the set
from the set ![[1..m]](https://s0.wp.com/latex.php?latex=%5B1..m%5D&bg=ffffff&fg=444444&s=0&c=20201002) and Bob has a number
and Bob has a number  from the set
from the set ![[1..n]](https://s0.wp.com/latex.php?latex=%5B1..n%5D&bg=ffffff&fg=444444&s=0&c=20201002) . They want to evaluate a function
. They want to evaluate a function  of the two numbers they have. The way they communicate with each other is as follows. Alice sends one bit to Bob, then Bob sends one bit to Alice, then Alice sends one bit to Bob and so on. Both of them have unlimited memory and unlimited processing power, so they can do extremely complicated things for deciding what bit they should send in each step. What’s the number of bits they will have to exchange in order to be able to evaluate
of the two numbers they have. The way they communicate with each other is as follows. Alice sends one bit to Bob, then Bob sends one bit to Alice, then Alice sends one bit to Bob and so on. Both of them have unlimited memory and unlimited processing power, so they can do extremely complicated things for deciding what bit they should send in each step. What’s the number of bits they will have to exchange in order to be able to evaluate  ?
? mod 2. In that case, all they would need is an exchange of 1 bit. Alice would send
mod 2. In that case, all they would need is an exchange of 1 bit. Alice would send  matrix
matrix  that encodes the values of
that encodes the values of ![F[i, j] = f(i, j)](https://s0.wp.com/latex.php?latex=F%5Bi%2C+j%5D+%3D+f%28i%2C+j%29&bg=ffffff&fg=444444&s=0&c=20201002) . Now consider any subset of rows and any subset of columns. The elements lying in a row of this subset and a column of this subset simultaneously form a rectangle, in the sense that there exists some permutation of the rows and the columns of the matrix for which the elements would lie inside a rectangular box. Let’s call such a rectangle monochromatic if
. Now consider any subset of rows and any subset of columns. The elements lying in a row of this subset and a column of this subset simultaneously form a rectangle, in the sense that there exists some permutation of the rows and the columns of the matrix for which the elements would lie inside a rectangular box. Let’s call such a rectangle monochromatic if 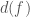 be the minimum number of monochromatic rectangles with which one can cover the whole matrix
be the minimum number of monochromatic rectangles with which one can cover the whole matrix 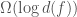 .
. . This shows that for most functions, the communication complexity is
. This shows that for most functions, the communication complexity is  .
. monochromatic rectangles, does this give us a protocol that uses
monochromatic rectangles, does this give us a protocol that uses  bits of communication? Theorem 2 from the paper says that it does as long as the decomposition satisfies the property that all its rectangles are contiguous. For general decompositions though, all that can be guaranteed is that there exists a protocol that uses
bits of communication? Theorem 2 from the paper says that it does as long as the decomposition satisfies the property that all its rectangles are contiguous. For general decompositions though, all that can be guaranteed is that there exists a protocol that uses  bits of communication.
bits of communication. and the second point
and the second point  . Assume that this is the axis of your cylinder and whenever a new point is shown, calculate the distance of that point from the line
. Assume that this is the axis of your cylinder and whenever a new point is shown, calculate the distance of that point from the line 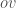 . If this distance is bigger than the previous maximum, then update. Whatever you have in the end is the radius of the cylinder. Is this algorithm good? Or in other words, can we say that the radius that we have in the end is at most some constant times the radius of the actual minimum enclosing cylinder? No, we can’t. The reason is that it might turn out that
. If this distance is bigger than the previous maximum, then update. Whatever you have in the end is the radius of the cylinder. Is this algorithm good? Or in other words, can we say that the radius that we have in the end is at most some constant times the radius of the actual minimum enclosing cylinder? No, we can’t. The reason is that it might turn out that  is really close to
is really close to  and all the other points that we get are really really far away from
and all the other points that we get are really really far away from 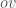 , but are very close to the perpendicular bisector of
, but are very close to the perpendicular bisector of  is the distance between the point
is the distance between the point  and the line
and the line  be the radius of the minimum enclosing cylinder of the points
be the radius of the minimum enclosing cylinder of the points 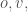 and
and 
 , then that gives an upper bound on the distance between
, then that gives an upper bound on the distance between 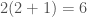 times the radius of the minimum enclosing cylinder of the points
times the radius of the minimum enclosing cylinder of the points  and
and 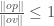 and therefore we will know that the radius we return will be at most 4 times the radius of the actual minimum enclosing cylinder.
and therefore we will know that the radius we return will be at most 4 times the radius of the actual minimum enclosing cylinder. to the radius
to the radius  initially. Next, whenever it encounters a new point
initially. Next, whenever it encounters a new point 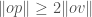 , then change
, then change  are the different values that
are the different values that 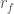 is the final value of
is the final value of 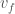 were obviously close to
were obviously close to  (when compared to
(when compared to  was small. The points that came between
was small. The points that came between 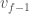 and
and  for the same reason. Also, since
for the same reason. Also, since  is also not more than 2, we know that
is also not more than 2, we know that 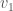 and
and  were close to
were close to 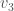 and therefore were also close to
and therefore were also close to  and so on till
and so on till  as its radius contains all the points. The reason why it is a good cylinder to return is that the minimum enclosing cylinder has its radius at least as large as
as its radius contains all the points. The reason why it is a good cylinder to return is that the minimum enclosing cylinder has its radius at least as large as  time. However, if you have been given, in addition, a non self-intersecting curve passing through all the points and the order in which the points occur along the curve, then the convex hull can be found in linear time. I find it a bit surprising that a non self-intersecting curve passing through all the points actually contains sufficient information to remove the
time. However, if you have been given, in addition, a non self-intersecting curve passing through all the points and the order in which the points occur along the curve, then the convex hull can be found in linear time. I find it a bit surprising that a non self-intersecting curve passing through all the points actually contains sufficient information to remove the 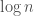 factor from the run-time of an algorithm. What are some other places where this information helps?
factor from the run-time of an algorithm. What are some other places where this information helps?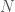 points in the plane are studied, such as finding a Euclidean minimum spanning tree, the smallest circle enclosing the set,
points in the plane are studied, such as finding a Euclidean minimum spanning tree, the smallest circle enclosing the set,  nearest and farthest neighbors, the two closest points, and a proper straight-line triangulation. For most of the problems considered a lower bound of
nearest and farthest neighbors, the two closest points, and a proper straight-line triangulation. For most of the problems considered a lower bound of 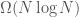 is shown. For all of them the best currently-known upper bound is
is shown. For all of them the best currently-known upper bound is  or worse. The purpose of this paper is to introduce a single geometric structure, called the Voronoi diagram, which can be constructed rapidly and contains all of the relevant proximity information in only linear space. The Voronoi diagram is used to obtain
or worse. The purpose of this paper is to introduce a single geometric structure, called the Voronoi diagram, which can be constructed rapidly and contains all of the relevant proximity information in only linear space. The Voronoi diagram is used to obtain  algorithms for all of the problems.
algorithms for all of the problems.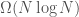 lower bound applies only to most of the problems. In particular, the smallest enclosing circle problem has a linear time algorithm.
lower bound applies only to most of the problems. In particular, the smallest enclosing circle problem has a linear time algorithm.