Assuming P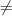 NP, an NP-hard problem cannot be solved in polynomial time. This means that there cannot exist an algorithm that, for all possible inputs, computes the corresponding output in polynomial time. However, NP-harndess doesn’t prohibit the existence of an efficient algorithm for only a subset of the possible inputs. For example, there is a constant time algorithm for any problem that solves it for a constant number of instances. The algorithm just has a lookup table where the outputs of all the constant number of inputs are stored.
NP, an NP-hard problem cannot be solved in polynomial time. This means that there cannot exist an algorithm that, for all possible inputs, computes the corresponding output in polynomial time. However, NP-harndess doesn’t prohibit the existence of an efficient algorithm for only a subset of the possible inputs. For example, there is a constant time algorithm for any problem that solves it for a constant number of instances. The algorithm just has a lookup table where the outputs of all the constant number of inputs are stored.
But this is an extreme case. Can there exist an algorithm for an NP-hard problem that solves it in polynomial time for a significantly large number of input instances? Or, more precisely, does there exist an algorithm, that, for all  , solves the problem in polynomial time for
, solves the problem in polynomial time for  inputs of size , where is some fast growing function of ?
inputs of size , where is some fast growing function of ?
How fast growing should be? One interesting choice for is something that makes the average case complexity of the algorithm polynomial, i.e., if inputs are chosen uniformly at random from the set of all inputs, then the algorithm takes polynomial time in expectation. Of course, will have to be fairly large for this to happen.
The interesting fact is that this is possible. For example, if you pick a graph on vertices randomly, with a distribution that is uniform over all graphs with vertices, then there exists an algorithm that decides whether the graph is hamiltonian or not in expected polynomial time.



