Once upon a time, an idiosyncratic king set up a peculiar system for settling marriages in his kingdom. Once every year, he would invite all the couples that wished to tie the knot to a grand ceremony. Upon arrival, the couples would be taken to a large open area with chairs that were fixed to the ground spread all around and asked to get seated. The arrangements would be so made that the chairs would neither be surplus nor in shortage. Thus each individual would get exactly one chair and no more.
Finally, the king himself would arrive, examine the seated guests, draw one long line on the ground and stand on one of its two sides. That’s when the marriages would be decided. Couples where both partners were seated on the side of the line the king stood on would get married and couples separated by the holy line would be forbidden from seeing each other ever again.
The king wanted to slow down the recent exponential growth in population in his kingdom and so he wanted as few couples to be married as possible. Since he had complete knowledge of who wanted to get married to whom, he could, in principle, devise an evil arrangement of chairs and draw one really mean line that would separate most of the couples at the ceremony. On the other hand, the couples were allowed to collude with each other upon seeing the arrangement of chairs and decide who got to sit where. Thus perhaps they could formulate a clever strategy that would let most of them be on the same side as the king no matter what line he chose to draw?
Year after year passed by and the king, drawing upon the wisdom of the entire royal ministry, managed to hoodwink his people and successfully stalled most of the romance in his kingdom. The lack of expertise in computational geometry among the general public proved to be detrimental to them. The grand ceremony, having the flavor of a gripping puzzle, got the king addicted and very soon, by developing progressively sophisticated and elaborate strategies, he unknowingly brought his own kingdom to what could be described as extinction.
Centuries later, in the year 1989, two researchers, trying to design an efficient data structure to perform range searching queries on a point-set proved an interesting theorem. They weren’t aware that the theorem held the key to a centuries old conundrum that could have saved an entire kingdom from going extinct. What they proved essentially amounted to this:
“No matter what the arrangement of chairs, the couples can always collude with each other and compute an assignment of chairs to each individual, so that no matter what line the king draws and no matter what side he stands on, at least a polynomial number of them get married.”
In fact, they proved something even stronger. Their theorem does not so much depend on the fact that the shape the king draws is a line. Other geometric shapes, such as circles, rectangles, squares, triangles, can all be plugged into the theorem in place of “line” and the statement will still hold true.
As long as the shape satisfies the property that its dual shatter function is polynomial, the theorem works. The dual shatter function for a shape is the maximum number of cells one can get in a Venn diagram obtained by drawing 
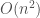
Actually, the theorem does not just hold in the geometric setting. It holds for general set systems. Thus if the ceremony were organized in interstellar space with chairs occupying co-ordinates in three dimensions, or in some bizarre abstract space, a polynomial number of marriages could be saved as long as the shape chosen by the king had a polynomial dual shatter function.
(Bonus points if you can correctly guess the definition of stabbing number without looking it up.)

 edges has a maximum independent set of size at least
edges has a maximum independent set of size at least  .
.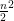 edges and an independent set of size
edges and an independent set of size  .
.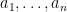 , the mean is the number that minimizes the function
, the mean is the number that minimizes the function  . Thus the averaging step above can be seen as a step where a person is trying to minimize the cost incurred with respect to the cost function
. Thus the averaging step above can be seen as a step where a person is trying to minimize the cost incurred with respect to the cost function 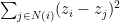 . Here
. Here  represents the neighborhood of
represents the neighborhood of  , i.e., the set of friends of
, i.e., the set of friends of  different bins?
different bins? .
. .
.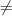 NP, an NP-hard problem cannot be solved in polynomial time. This means that there cannot exist an algorithm that, for all possible inputs, computes the corresponding output in polynomial time. However, NP-harndess doesn’t prohibit the existence of an efficient algorithm for only a subset of the possible inputs. For example, there is a constant time algorithm for any problem that solves it for a constant number of instances. The algorithm just has a lookup table where the outputs of all the constant number of inputs are stored.
NP, an NP-hard problem cannot be solved in polynomial time. This means that there cannot exist an algorithm that, for all possible inputs, computes the corresponding output in polynomial time. However, NP-harndess doesn’t prohibit the existence of an efficient algorithm for only a subset of the possible inputs. For example, there is a constant time algorithm for any problem that solves it for a constant number of instances. The algorithm just has a lookup table where the outputs of all the constant number of inputs are stored. inputs of size
inputs of size 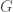 with a separating triangle
with a separating triangle  .
. 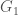 and
and 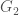 such that
such that  and
and  . If
. If  of maximal planar graphs without any separating triangles. Now, consider a graph whose nodes represent elements of the set
of maximal planar graphs without any separating triangles. Now, consider a graph whose nodes represent elements of the set  . The theorem by Jackson and Yu states that if
. The theorem by Jackson and Yu states that if  from the set
from the set ![[1..m]](https://s0.wp.com/latex.php?latex=%5B1..m%5D&bg=ffffff&fg=444444&s=0&c=20201002) and Bob has a number
and Bob has a number  from the set
from the set ![[1..n]](https://s0.wp.com/latex.php?latex=%5B1..n%5D&bg=ffffff&fg=444444&s=0&c=20201002) . They want to evaluate a function
. They want to evaluate a function  of the two numbers they have. The way they communicate with each other is as follows. Alice sends one bit to Bob, then Bob sends one bit to Alice, then Alice sends one bit to Bob and so on. Both of them have unlimited memory and unlimited processing power, so they can do extremely complicated things for deciding what bit they should send in each step. What’s the number of bits they will have to exchange in order to be able to evaluate
of the two numbers they have. The way they communicate with each other is as follows. Alice sends one bit to Bob, then Bob sends one bit to Alice, then Alice sends one bit to Bob and so on. Both of them have unlimited memory and unlimited processing power, so they can do extremely complicated things for deciding what bit they should send in each step. What’s the number of bits they will have to exchange in order to be able to evaluate  ?
? mod 2. In that case, all they would need is an exchange of 1 bit. Alice would send
mod 2. In that case, all they would need is an exchange of 1 bit. Alice would send  matrix
matrix  that encodes the values of
that encodes the values of ![F[i, j] = f(i, j)](https://s0.wp.com/latex.php?latex=F%5Bi%2C+j%5D+%3D+f%28i%2C+j%29&bg=ffffff&fg=444444&s=0&c=20201002) . Now consider any subset of rows and any subset of columns. The elements lying in a row of this subset and a column of this subset simultaneously form a rectangle, in the sense that there exists some permutation of the rows and the columns of the matrix for which the elements would lie inside a rectangular box. Let’s call such a rectangle monochromatic if
. Now consider any subset of rows and any subset of columns. The elements lying in a row of this subset and a column of this subset simultaneously form a rectangle, in the sense that there exists some permutation of the rows and the columns of the matrix for which the elements would lie inside a rectangular box. Let’s call such a rectangle monochromatic if 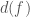 be the minimum number of monochromatic rectangles with which one can cover the whole matrix
be the minimum number of monochromatic rectangles with which one can cover the whole matrix 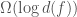 .
. . This shows that for most functions, the communication complexity is
. This shows that for most functions, the communication complexity is  .
. monochromatic rectangles, does this give us a protocol that uses
monochromatic rectangles, does this give us a protocol that uses  bits of communication? Theorem 2 from the paper says that it does as long as the decomposition satisfies the property that all its rectangles are contiguous. For general decompositions though, all that can be guaranteed is that there exists a protocol that uses
bits of communication? Theorem 2 from the paper says that it does as long as the decomposition satisfies the property that all its rectangles are contiguous. For general decompositions though, all that can be guaranteed is that there exists a protocol that uses  bits of communication.
bits of communication. and the second point
and the second point  . Assume that this is the axis of your cylinder and whenever a new point is shown, calculate the distance of that point from the line
. Assume that this is the axis of your cylinder and whenever a new point is shown, calculate the distance of that point from the line 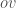 . If this distance is bigger than the previous maximum, then update. Whatever you have in the end is the radius of the cylinder. Is this algorithm good? Or in other words, can we say that the radius that we have in the end is at most some constant times the radius of the actual minimum enclosing cylinder? No, we can’t. The reason is that it might turn out that
. If this distance is bigger than the previous maximum, then update. Whatever you have in the end is the radius of the cylinder. Is this algorithm good? Or in other words, can we say that the radius that we have in the end is at most some constant times the radius of the actual minimum enclosing cylinder? No, we can’t. The reason is that it might turn out that  is really close to
is really close to  and all the other points that we get are really really far away from
and all the other points that we get are really really far away from 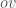 , but are very close to the perpendicular bisector of
, but are very close to the perpendicular bisector of  is the distance between the point
is the distance between the point  and the line
and the line  be the radius of the minimum enclosing cylinder of the points
be the radius of the minimum enclosing cylinder of the points 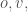 and
and 
 , then that gives an upper bound on the distance between
, then that gives an upper bound on the distance between 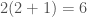 times the radius of the minimum enclosing cylinder of the points
times the radius of the minimum enclosing cylinder of the points  and
and 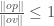 and therefore we will know that the radius we return will be at most 4 times the radius of the actual minimum enclosing cylinder.
and therefore we will know that the radius we return will be at most 4 times the radius of the actual minimum enclosing cylinder. to the radius
to the radius  initially. Next, whenever it encounters a new point
initially. Next, whenever it encounters a new point 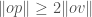 , then change
, then change  are the different values that
are the different values that 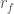 is the final value of
is the final value of 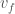 were obviously close to
were obviously close to  (when compared to
(when compared to  was small. The points that came between
was small. The points that came between 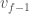 and
and  for the same reason. Also, since
for the same reason. Also, since  is also not more than 2, we know that
is also not more than 2, we know that 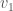 and
and  were close to
were close to 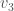 and therefore were also close to
and therefore were also close to  and so on till
and so on till  as its radius contains all the points. The reason why it is a good cylinder to return is that the minimum enclosing cylinder has its radius at least as large as
as its radius contains all the points. The reason why it is a good cylinder to return is that the minimum enclosing cylinder has its radius at least as large as  time. However, if you have been given, in addition, a non self-intersecting curve passing through all the points and the order in which the points occur along the curve, then the convex hull can be found in linear time. I find it a bit surprising that a non self-intersecting curve passing through all the points actually contains sufficient information to remove the
time. However, if you have been given, in addition, a non self-intersecting curve passing through all the points and the order in which the points occur along the curve, then the convex hull can be found in linear time. I find it a bit surprising that a non self-intersecting curve passing through all the points actually contains sufficient information to remove the 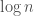 factor from the run-time of an algorithm. What are some other places where this information helps?
factor from the run-time of an algorithm. What are some other places where this information helps?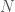 points in the plane are studied, such as finding a Euclidean minimum spanning tree, the smallest circle enclosing the set,
points in the plane are studied, such as finding a Euclidean minimum spanning tree, the smallest circle enclosing the set,  nearest and farthest neighbors, the two closest points, and a proper straight-line triangulation. For most of the problems considered a lower bound of
nearest and farthest neighbors, the two closest points, and a proper straight-line triangulation. For most of the problems considered a lower bound of 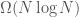 is shown. For all of them the best currently-known upper bound is
is shown. For all of them the best currently-known upper bound is  or worse. The purpose of this paper is to introduce a single geometric structure, called the Voronoi diagram, which can be constructed rapidly and contains all of the relevant proximity information in only linear space. The Voronoi diagram is used to obtain
or worse. The purpose of this paper is to introduce a single geometric structure, called the Voronoi diagram, which can be constructed rapidly and contains all of the relevant proximity information in only linear space. The Voronoi diagram is used to obtain  algorithms for all of the problems.
algorithms for all of the problems.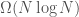 lower bound applies only to most of the problems. In particular, the smallest enclosing circle problem has a linear time algorithm.
lower bound applies only to most of the problems. In particular, the smallest enclosing circle problem has a linear time algorithm.