(Disclaimer: I know nothing about Economics.)
From the point of view of economics, the world consists of:
- A set of people.
- A set of assets.
- A set of ownerships between people and assets.
#2 and #3 deserve some explanation. #1 should be clear to you if you are not an alien.
What is an asset? I want to make the definition very general and say that anything that can be owned is an asset. So, a pair of shoes is an asset, an iPhone is an asset, and so is a car. Time is also an asset, although a more subtle one. I will come back to this later and provide some more non-trivial examples of assets.
An ownership is just a pair consisting of one person and one asset. Given a set of ownerships, each person will be a part of several pairs and the set of assets in those pairs will be the assets owned by that person. A society where there is a mechanism to enforce ownerships will be amenable to various laws of economics. What do I mean by enforcing ownership? That the set of ownerships remains unchanged unless two people decide, by mutual consent, to exchange a few assets that they own. An exchange of assets is usually called a trade.
If a person combines a few of the assets he owns to create a new asset, the new asset is automatically considered to be owned by him. So if you have the ingredients for making ketchup and you use your time, which is an asset owned by you, to make ketchup, the ketchup will be considered to be owned by you.
The meaning of consent needs clarification. It’s one of the trickiest things to define and I am not going to claim that I have the most satisfactory definition. Use of physical force is clearly not consent. It’s robbery. But how about using mental tricks? It seems clear that if you drug someone and steal their wallet, they did not consent to give you their wallet. However, what if you use advanced marketing tricks to convince them to empty half their wallet for a weight-reduction armwear that clearly doesn’t work? That sounds like consent.
I am going to completely sidestep the task of defining consent by just stating its desired property. I will say that any trade that ends up increasing the perceived utility of both parties was carried out by mutual consent. That is, both parties involved in the trade should think that the trade improved their lives. As long as this happens, we will say that the trade happened with mutual consent. Note that this definition fits the examples discussed above. In case of physical force, the party on whom the physical force was applied definitely doesn’t think they are better off now. But in case of using marketing tricks, the person who bought the weight-reduction armwear does believe the purchase to be progress. In fact, that’s the point of marketing: to convince the customers that buying the product will make them richer, happier, sexier, and healthier.
With these definitions in place, if we assume that every individual has sufficient resources (intelligence and information) to figure out what’s good for them in the long term, then we get a simple and elegant model of governance: just make sure that all trades are carried out by mutual consent. The assumption that each individual knows what’s good for them is essentially saying that the perceived utility is always the same as the correct utility, and if that’s true, every trade must improve the correct utilities of both parties involved.
 different coupons. How many pizzas do you need to buy on average in order to collect all possible coupons? We know from kindergarten that the answer is
different coupons. How many pizzas do you need to buy on average in order to collect all possible coupons? We know from kindergarten that the answer is 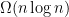 . Here’s an intuitive explanation why.
. Here’s an intuitive explanation why. is being tossed repeatedly. How many times, on average, does it need to be tossed to get a heads for the first time? I promise this is related, and the relation will be clear soon.
is being tossed repeatedly. How many times, on average, does it need to be tossed to get a heads for the first time? I promise this is related, and the relation will be clear soon.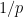 for our answer. Intuitively, it does look like that should be the answer, since if we rolled a die with
for our answer. Intuitively, it does look like that should be the answer, since if we rolled a die with  be the expected number of tosses need. Then if the first toss shows a heads, we know that
be the expected number of tosses need. Then if the first toss shows a heads, we know that  . Writing this “in math” we get
. Writing this “in math” we get  , which solves to
, which solves to  .
. coupons. What’s the probability that if we buy a pizza, we get a coupon that we do not already have? Clearly,
coupons. What’s the probability that if we buy a pizza, we get a coupon that we do not already have? Clearly,  . Thus the expected number of pizzas needed to get one new coupon, from the previous calculations, is
. Thus the expected number of pizzas needed to get one new coupon, from the previous calculations, is  . This means the expected number of pizzas required to collect all coupons can just be written as a the sum
. This means the expected number of pizzas required to collect all coupons can just be written as a the sum  , which solves to
, which solves to 