Reinforcement learning is an attempt at solving an extremely general and difficult problem.
Think about how we live our lives. Every minute we are presented with some decision. It could be something minor, such as “Should I scratch that itch?” or something major, such as “Should I move to this new city?”. Our choices determine what happens next. Some outcomes are bad and they teach us not to make similar choices in the future, and some outcomes feel nice and encourage us to repeat our behaviour. Over time, if we’re smart, we learn how to achieve a reasonable level of happiness. This learning process is what we want to understand better.
Reinforcement learning is a way to model this sort of learning process. When we try to say the above with more precision, we get reinforcement learning.
We first define a set 
Next, we approximate the whole universe with one symbol: 
In the framework of reinforcement learning, we assume that the universe is governed by some process that can be partially influenced by our actions. We can think of this as a game. The universe starts in some state 
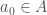


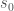
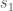
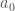
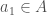
There are some issues that need to be carefully thought out to make this definition precise:
- What exactly do we mean by long-term reward? It sounds like something along the lines of
. But if the game goes on forever, this sum may have no guarantee to converge and we may end up with strategies that give us an undefined amount of long-term reward. If that doesn’t happen, we always get an infinite amount of total reward and thus finding an optimal strategy gets trivial. There are two popular ways to handle this issue. One option is to assume that the game ends at some point. This is enforced by including a state
in
for some constant
.
- How exactly does the universe decide the next state to be in? One option is to say that there’s a function
that the universe uses to determine the next state given current state and action. This, however, makes things deterministic in the sense that for a given state and action, the next state is fully determined. We may want to relax that and add some randomness by defining the function as
where
now denotes the probability of going from a state to another when a certain action is taken. This function is usually called the transition function. One might ponder if this relaxation is really needed. If we observe a universe where if we take an action
in state
sometimes it goes to state
and sometimes to
could it be because we haven’t modelled the universe with a rich enough set of states? Perhaps we could capture some extra information in the set
- Continuing on the previous point, is it fair to constrain the universe to only use the current state, and not the whole sequence of previous states, to decide on the next state? As long as we have no constraints on the definition of
- Turning our focus to the player, how does the player decide what action to pick next? Let’s model this in a similar way. The player uses a deterministic function
, that given a state returns an action to take. This function is called the policy. If we fix the set of states,
that is the best policy, i.e., it maximizes the long term reward of the game. Even if
- We can then define learning as the task of figuring out the optimal policy. If the player knows
Let’s step back a bit again so we don’t lose sight of the big picture and see what kinds of problems can be cast as a reinforcement learning problem. We already saw in the beginning that life is a reinforcement learning problem.
A variety of scientific fields can in fact be cast as reinforcement learning. For example, all of physics is a reinforcement learning problem as follows: let
One can also very easily cast “making money” as a reinforcement learning problem. Of course, since life itself is reinforcement learning, it’s no surprise that making money is too. But more specifically, one can pick the set of actions to be the set of all investments one can possibly make at any given time. The optimal policy in this case would be the one that maximizes the return on investments. Thus someone claiming to have solved reinforcement learning has also solved all of finance and the hedge fund industry doesn’t need to exist any more.
In fact, the problem of reinforcement learning is so general that it’s a surprise that it’s solvable at all! And yet, some recent research has shown remarkable capabilities at being able to solve it. For example, if you haven’t been living under a rock, you have probably heard of DeepMind’s algorithm that managed to learn all of Go, chess, and shogi without having given any domain knowledge about the individual games. Merely by playing the games over and over again and observing the rewards, the algorithm figured out how to beat the world champion programs in all three games. That’s getting closer and closer to solving all of life!
In this series, we will explore the frontier of this very exciting field. We will delve deep into some of the recent work and try to develop an understanding of what makes reinforcement learning solvable in certain domains and what can be done to make it solvable in others.
